Każdy kto kiedykolwiek pracował w technologii JSF wie że rozbudowana nawigacja na stronie może przysporzyć wiele problemów. Z pomocą w takich wypadkach przychodzi specyfikacja Spring Web-Flow, która z łatwością integruje się z JSF'em.
Wprowadzenie do JSF.
Model nawigacji technologii JavaServerFaces jest zbiorem zasad określających, która strona zostanie otwarta po naciśnięciu przez użytkownika przycisku lub hiperłącza.Zasady nawigacji definiowane są w pliku
faces-config.xml w formie testowych etykiet związanych z danymi widokami. W technologii JSF wyróżniamy dwa rodzaje nawigacji: statyczną, używaną w prostych aplikacjach oraz dynamiczną.
NAWIGACJA STATYCZNA
W nawigacji statycznej zatwierdzenie formularza generuje komunikat, który po porównaniu zawsze prowadzi do tej samej strony, zdefiniowanej w faces-config.xml.
np.:
<navigation-rule>
<from-view-id>/greeting.jsp</from-view-id>
<navigation-case>
<from-outcome>success</from-outcome>
<to-view-id>/response.jsp</to-view-id>
</navigation-case>
</navigation-rule>
Znacznik
<from-view-id> określa z jakiej strony- widoku przechodzimy,
znacznik
<to-view-id> określa do jakiej strony przechodzimy,
a znacznik
<from-outcome> określa warunek przejścia pomiędzy tymi widokami.
W powyższym przykładzie reguła nawigacji określa, że w przypadku zatwierdzenia formularza na stronie greting.jsp użytkownik zostanie przekierowany do strony response.jsp, jeżeli system nawigacji dostanie etykietę „success”. Reguły nawigacji mogą zawierać dowolną liczbę elementów <navigation-case>, z których każdy określa stronę do której nastąpi przekierowanie (<to-view-id>) w przypadku określonej etykiety (<from-outcome>).
Przekierowanie na stronie możemy sobie zdefiniować poprzez:
<h:commandButton id="submit" action="success" value="Submit"/>
Atrybut action jest porównywany z wartością określoną w <from-outcome>.
W przypadku braku dopasowania strona przekieruje się na siebie.
NAWIGACJA DYNAMICZNA
W bardziej skomplikowanych aplikacjach etykieta nawigacji może zostać określona na podstawie zwróconej wartości metody akcji w BackingBean. Tym sposobem możemy np. przekierować użytkownika do konkretnej strony, gdy formularz zostanie wypełniony poprawnie i do strony obsługującej błąd w przeciwnym przypadku. W celu implementacji dynamicznej nawigacji należy utworzyć metodę akcji, która w zależności od danych wprowadzonych do formularza zwróci jedną z etykiet nawigacji,
np.
public String login(){
if pin.equals(„123”)
return “success”;
else return “failure”;
}
Natomiast w definicji przycisku formularzu, wartość etykiety nawigacji w atrybucie ACTION nie jest podawana statycznie, ale w postaci w wyrażenia języka wyrażeń, wywołującego metodę akcji komponentu BackingBean,
np.
<h:commandButton id = „submit”
Action=”#{LoginBean.login}”value=”Submit”/>
Gdy użytkownik wejdzie na stronę index.jps zostanie przekierowany do
registrationhome.jsp.
Z tej strony istnieje tylko jedno przejście które jest dopasowywane na podstawie komunikatu <<welcome>>. Po wywołaniu odnośnika JSF sprawdza komunikaty zdefiniowane w faces-config.xml i na tej podstawie przekierowuje stronę.
Obydwa podejścia wydają się proste i kompleksowe, w praktyce jednak mogą pojawić się nieoczekiwane problemy. JavaServerFaces w zamierzeniu ma być potężnym frameworkiem , który upraszcza tworzenie interfejsu użytkownika do aplikacji Java EE. W praktyce mechanizm przepływ sterowania w technologii JSF ma szereg ograniczeń wynikających z jego prostoty. (tak prostota może powodować ograniczenia).
Problemy z działaniem mechanizmu pojawiają się przypadku bardziej złożonych zastosowań, szczególnie przy modelowaniu złożonej logiki biznesowej cechującej wieloma przejściami pomiędzy stronami. Czym więcej przejść tym trudniej określać reguły nawigacyjne, a co za tym idzie testować całą aplikacje.
JSF posiada słabsze standardowe komponenty walidujące oraz zawodzi w przypadku definiowania zasad określających przeznaczenie i przekierowywanie stron nie będących szablonami JSF, podobnie jak w przypadku obsługi wyjątków.Największą wadą tego mechanizmu jest mała wydajność w stosunku do integracji z frameworkami rozszerzającymi JSF'a np: MyFaces.
PRZYKŁAD PROSTEJ APLIKACJI. OPIS PROBLEMU
Jako przykład pokażmy prostą aplikacje do rejestracji, która będzie składała się z paru stron które pozwolą użytkownikowi na zarejestrowanie się w systemie.Po utworzeniu wszystkich stron wraz z formularzem możemy przejść do definiowania przejść pomiędzy stronami.
Rysunek poniżej przedstawia przepływ sterowania dla aplikacji.
Kiedy użytkownik wejdzie na stronę index.jsp zostanie automatycznie przekierowany do
registrationhome.jsp. Tutaj jedyną opcją jest naciśnięcie dostarczonego linku, który wygeneruje wiadomość welcome, która następnie zostanie zinterpretowana przez JSF'a.
Kolejne przekierowanie zostanie wyznaczone na podstawie konfiguracji w pliku
faces-config.xml.
Kolejną stroną jest
courseregister.jsp z której użytkownik może się cofnąć, generując komunikat cancel, albo kontynuować klikając na Register. Po wywołaniu Register użytkownik zostaje przekierowany do strony
cocourseconfirm.jsp, na której może edytować, bądź potwierdzić dane rejestracji.
Na podstawie tego prostego przykładu można wyodrębnić dość powszechny problem.
W przypadku, gdy użytkownik znajdujący się na stronie
courseregister.jsp wypełni niepoprawnie pola z danymi ( np. walidacja pól co do długości znaków) to po wygenerowaniu komunikatu cancel nie zostanie on przekierowany do głównej strony. Zamiast tego na stronie pojawią się komunikaty o źle wypełnionych danych.
Dzieje się tak, gdyż po wysłaniu formularza zostaje przeprowadzona walidacja, a co za tym idzie strona jest przekierowywana na siebie samą z wygenerowaniem komunikatu o błędzie. Aby pominąć ten błąd należy użyć atrybutu zwanego immediate, który pozwoli na wykonanie przekierowania przed walidacją, co uchroni nas przed tym błędem.
<h:commandButton value="Cancel"
action="cancel" immediate="true">
</h:commandButton>
Wyobraźmy sobie sytuacje w której nasza rejestracja będę ciągle rozbudowywana
np. podzielona na rejestracje dla pracowników i firm zewnętrznych.
W takim przypadku potrzebujemy bardziej konfigurowalnego środowiska do zarządzania przepływem stron.
NIESTANDARDOWY MECHANIZM NAWIGACJI
Kolejnym krokiem jest stworzenie rozwiązania, które pozwoli na konfigurację zasad w aplikacji JSF. JSF udostępnia nam natywny sposób do włączenia niestandardowej obsługi nawigacji. W JSFie za przekierowania odpowiada element NavigationHandler, można jednak stworzyć własną obsługę poprzez
CustomNavigationHandler. W takim wypadku proces od wygenerowania żądania do odpowiedzi wygląda w następujący sposób:
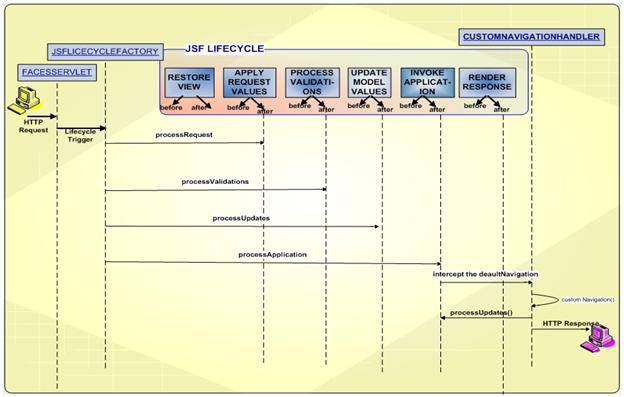
Jak widać proces ten wymaga napisania CustomNavigationHandler i zarejestrowania go w pliku faces-config.xml. To rozwiązanie daje developerowi nieograniczone możliwości. Dzięki temu można tworzyć nawigacje dla stron nie jsfowych, np. stworzonych w Struts 2. Jak się jednak okazuje nie ma potrzeby na przedefiniowanie domyślnej obsługi, gdyż istnieje wiele darmowych frameworków, które pozwalają w prosty sposób rozwiązać problemy z nawigacją... i tutaj pojawia się framework Spring Web Flow.
Wprowadzenie do Spring Web Flow
CHARAKTERYSTYKA WEBFLOW
Jednym z takich rozwiązań jest Spring WebFlow. Web Flow jest frameworkiem, który pozwala definiować przepływ sterowania w aplikacjach internetowych. Jest on swego rodzaju odpowiedzią na ograniczone funkcjonalności przepływu stron w klasycznych frameworkach MVC (JSF, Struts itp).
Web Flow integruje się ze Springiem, JSF'em i Struts, pozwalając przy tym na definiowanie przepływu stron składających się z widoków(ekran) i akcji(kod), pozwalając na ponowne użycie przepływu danej strony.
Filozofia Web Flow sprawia że każda strona może być rozrysowana jako prosty diagram stanów, w którym każdy stan w przepływie wiąże się ze stroną i wykonaniem kodu. Stan jest punktem w przepływie w którym dokonało się jakieś zdarzenie, np. pokazanie widoku, czy wykonanie kodu. Ma on jedno bądź więcej przejść, które pozwalają na przejście do innych stanów. Definiowanie przejść pomiędzy tymi stanami pozwala nam na określenie przepływu dla aplikacji.
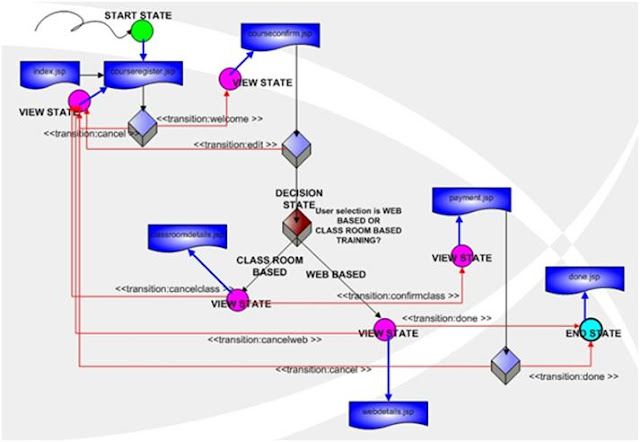
Powyższy diagram składa się ze stanu startowego, w którym rozpoczyna się pierwsza tranzycja WebFlow, stanu decyzji (decision state), w którym podejmowana jest decyzja
bazująca na wartości i stanu końcowego (end state) wskazującego miejsce z którego nie ma już żadnych tranzycji. Dzięki WebFlow dodawanie nowych wymagań jest kwestią dopisania paru linijek w pliku xml.
Zalety użycia WebFlow:
• Przepływ jest projektowany tak by był on w pełni niezależny.
Pozwala to na patrzenie na cześć aplikacji jak na moduł, który możemy wykorzystać w wielu sytuacjach.
• Przepływ może definiować dowolny sensowny przepływ dla warstwy interfejsu użytkownika, używając za każdym razem tej samej techniki. Nie musimy używać specjalistycznych kontrolerów w zależności od sytuacji.
KONFIGURACJA WEBFLOW
Aby móc używać WebFlow należy ściągnąć następujące biblioteki:
• spring-webflow (framework)
• spring-core ( różne klasy użytkowe są używane przez framework)
• spring-binding (Spring data binding framework)
• Apache commons-logging
• OGNL (domyślny język wyrażeń)
• Facelets ( wymagane przy użyciu SpringFaces)
IDE: Eclipse, Netbeans.
Pluginy do Eclipse: Spring IDE plugin, który osobiście polecam do pracy ze Springem MVC i Web-Flow.
Integracja JSF ze Spring WebFlow
WPROWADZENIE
Spring Faces jest wewnętrznym modułem Springa zdefiniowanym w celu ułatwienia integracji z JSF'em. Pozwala on na użycie komponentów UI JSF'a z kontrolerami Spring MVC i Spring WebFlow.
Spring Faces posiada także małą bibliotekę komponentów Facelet, która pozwala na zastosowanie Ajaxa czy też walidacji po stronie klienta.
ZALETY WYNIKAJĄCE Z INTEGRACJI
Spring Faces jest wewnętrznym komponentem Springa łączącym w sobie zalety komponentów interfejsu użytkownika z JSF z zaletami Springa, takimi jak model kontroli i nawigacji. W ten sposób uzyskujemy wszystkie zalety JSF wykluczając wszystkie wady.
Spring Faces dostarcza wielu dodatkowych funkcjonalności dołączanych do standardowych funkcji JSF'a takich jak:
• łatwość zarządzania ziarnami
• zarządzanie zasięgiem
• obsługę zdarzeń
• obsługę reguł nawigacji
• podział sytemu na mniejsze, spójne moduły i grupowanie widoków
• maskowanie adresów url (URL mapping)
• walidację po stronie klienta i ulepszony interfejs użytkownika
. obsługę zdarzeń Ajaxa
Powyższe funkcjonalności pozwalają na znaczną redukcję ilości konfiguracji wymaganej w faces-config.xml zapewniając jednocześnie czytelniejsze rozdzielenie warstwy widoku i warstwy kontrolera oraz lepszy podział funkcyjnych odpowiedzialności naszej aplikacji. Użycie tych funkcjonalności zostało opisane w dalszych sekcjach. Znaczna większość z tych funkcjonalności jest budowana za pomocną "flow definiction language" czyli jezyka definicji przepływu dla Spring WebFlow.
Aby w pełni zrozumieć zagadnienia opisywane w ramach integracji należy się zapoznać z podstawowymi zasadami definicji przepływów dla Spring WebFlow.
KONFIGURACJA PLIKU Web.xml
Pierwszym krokiem do używania Spring Faces jest przekierowanie requestów do DispatcherServlet. Możemy to wykonać edytując wpisy w pliku web.xml .
Najpierw definiujemy servlet:
<servlet>
<!-- Specyfikacja nazwy i klasy servletu -->
<servlet-name>Spring MVC Dispatcher Servlet</servlet-name>
<servlet class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<!-- Specyfikacja położenia konfiguracji-->
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/web-application-config.xml</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<!-- Mapowanie servletu na adresy url-->
<servlet-mapping>
<servlet-name>Spring MVC Dispatcher Servlet</servlet-name>
<url-pattern>/spring/*</url-pattern>
</servlet-mapping>
Sekcja init-param jest używana do zainicjowania parametrów. W tym przypadku specyfikuje ono lokacje pliku konfiguracji WebFlow dla naszej aplikacji. W przykładzie mapujemy wszystkie URL'e które zaczynają się od ciągu /spring/ na stworzony servlet.
Po zdefiniowaniu dispatcher'a musimy zdefiniować FacesServlet. Jest to konieczne gdyż jest on wykorzystywany przez mechanizmy JSF'a. Standardowo to on przekierowuje requesty jednak w przypadku integracji ze Springiem, nie będzie on wykorzystywany.
<!-- Inicjializacja implementacji JSF'a. Nie używana podczas pracy programu -->
<servlet>
<servlet-name>Faces Servlet</servlet-name>
<servlet-class>javax.faces.webapp.FacesServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>Faces Servlet</servlet-name>
<url-pattern>*.faces</url-pattern>
</servlet-mapping>
Używając komponentów Spring Faces, musimy zdefiniować Springowy ResourceServlet odpowiadający za JavaScript. Dzięki niemu pliki CSS i JavaScript będą mogły być prawidłowo aplikowane do komponentów. ResourceServlet musi być mapowany na url /resources/* aby adres URL renderowany przez komponenty funkcjonował poprawnie.
<!-- Obsługa niezmiennych zasobów z plików jar. -->
<servlet>
<servlet-name>Resource Servlet</servlet-name>
<servlet-class>org.springframework.js.resource.ResourceServlet</servlet-class>
<load-on-startup>0</load-on-startup>
</servlet>
<!-- Mapowanie wszystkich żądań /resources do servletu ResourceServlet do obsługi -->
<servlet-mapping>
<servlet-name>Resource Servlet</servlet-name>
<url-pattern>/resources/*</url-pattern>
</servlet-mapping>
Komponenty Spring Faces wymagają użycia Facelets (alternatywnej technologii obsługi widoku dla JSF'a), zamiast JSP. Typowa konfiguracja Facelets musi zostać dodana także podczas użycia tych komponentów. Facelets wymagają prawidłowych dokumentów XML. W praktyce oznacza to że wszystkie strony stworzone przy integracji muszą być prawidłowymi plikami XHTML. Wspierają one wszystkie komponenty wizualne JSF'a. Budują własne drzewo komponentów, odzwierciedlając widok dla aplikacji JSF.
<!-- Używa widoków opartych na szablonach JSF'a zapisanych jako *.xhtml-->
<context-param>
<param-name>javax.faces.DEFAULT_SUFFIX</param-name>
<param-value>.xhtml</param-value>
</context-param>
Dla optymalnej wydajności ładowania stron, biblioteka komponentów Spring Faces zawiera parę specjalnych komponentów includeStyles i includeScripts. Te komponenty przyspieszają ładowanie ważnych stylów CSS i plików JavaScript, w pozycji której zostały one umieszczone w szablonie widoku JSF'a. Zgodnie z rekomendacjami, te dwa tagi powinny być umieszczone w sekcji head każdej strony, która używa komponentów Spring Faces.
Na przykład:
...
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<title>Zaawansowane technologie WEB. Lab </title>
<sf:includeStyles />
<sf:includeScripts />
<ui:insert name="headIncludes"/>
</head>
...
Przykład pokazuje początek typowych layoutów XMTL Facelets które używają tych komponentów do wymuszenia ładowania potrzebnych stylów CSS i JavaScriptu w
idealnym miejscu. Komponent includeStyles dołącza potrzebne zasoby dla motywów widgetów Dojo. Jako domyślne dołączane są zasoby dla motywu "tundra".
Do wybrania alternatywnego tematu musimy ustawić opcjonalne atrybuty "theme" i "themePath" w komponencie includeStyles np:
<sf:includeStyles themePath="/styles/" theme="foobar"/>
Załaduje styl CSS z katalogu "/styles/foobar/foobar.css" używając Spring JavaScript ResourceServlet.
KONFIGURACJA WEBFLOW DO RENDEROWANIA WIDOKÓW JSF
Kolejnym krokiem będzie konfiguracja WebFlow do renderowania widoków JSF'a.
Aby to wykonać należy dołączyć przestrzeń nazw Faces do konfiguracji WebFlow i podłączyć flow-builder-services:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:webflow="http://www.springframework.org/schema/webflow-config"
xmlns:faces="http://www.springframework.org/schema/faces"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/webflow-config
http://www.springframework.org/schema/webflow-config/spring-webflow-config-2.0.xsd
http://www.springframework.org/schema/faces
http://www.springframework.org/schema/faces/spring-faces-2.0.xsd">
<!-- Wywołuje wykonywanie przepływu. Jest to główny punkt systemu WebFlow -->
<webflow:flow-executor id="flowExecutor" />
<!-- Rejestr definicji wykonywalnych przepływów -->
<webflow:flow-registry id="flowRegistry" flow-builder-services="facesFlowBuilderServices" base-path="/WEB-INF">
<webflow:flow-location-pattern value="**/*-flow.xml" />
</webflow:flow-registry>
<!-- Konfiguracja Spring Web Flow dla integracji z JSF ->
<faces:flow-builder-services id="facesFlowBuilderServices" />
</beans>
Etykieta faces:flow-builder-services konfiguruje kilka innych ustawień odpowiednich dla środowiska JSF.
KONFIGURACJA PLIKU faces-config.xml
Przy integracji jedyną konfiguracją potrzebną nam w pliku faces-config.xml jest określenie użycia Faceletów. W przypadku, gdy używamy komponentów JSP zamiast Spring Faces, nie musimy dodawać nic więcej do naszego pliku faces-config.xml.
<faces-config>
<application>
<!-- Enables Facelets -->
<view-handler>com.sun.facelets.FaceletViewHandler</view-handler>
</application>
</faces-config>
ZASTĘPOWANIE JSF MANAGED BEAN FACILITY
Spring Faces pozwala na całkowitą zamianę JSF managed bean facility z kombinacją zmiennych zarządzających przepływem ( flow-managed variables ) i Spring Managed beans.
Daje on nam o wiele większą kontrolę nad cyklem życia zarządzanych obiektów z dobrze zdefiniowanymi powiązaniami dla inicjowania i wykonania modelu dziedzinowego.
Dodatkową łatwością jest brak konieczności utrzymywania dwóch różnych modeli zarządzanych ziarnami.
W tworzeniu aplikacji poprzez użycie JSF'a, może się szybko okazać że zakres żądania nie jest dostępny na tyle długo by móc zapisywać obiekty modelu konwersacji.
Jedynym rozwiązaniem w takim przypadku jest umieszczanie elementów w zakresie sesji.
a) Używanie zmiennych przepływu.
Najprostszym i najbardziej naturalnym sposobem na deklarowanie i zarządzanie modelem jest użycie zmiennych przepływu (flow variables).
Możemy deklarować te zmienne na początku definicji przepływu:
<var name="searchCriteria" class="com.mycompany.myapp.hotels.search.SearchCriteria"/>
Stworzenie referencji do tej zmiennej w jednym z szablonów widoków JSF'a poprzez język wyrażeń.
<h:inputText id="searchString" value="#{searchCriteria.searchString}"/>
Nie musimy dodawać przedrostka zmiennej w tym zakresie gdy odwołujemy się do niej poprzez szablon.
Podobnie jak w przypadku standardowych ziaren JSF, wszystkie dostępne zakresy zmiennych będą przeszukane by dopasować zmienną, dlatego powinno się zmienić zakres zmiennej w definicji przepływu bez modyfikowania wyrażeń EL które się do nich odwołują.
Można także zdefiniować zmienne instancji widoków które będą dostępne w zakresie życia danego widoku. Po przejściu do następnego widoku takie zmienne będą automatycznie niedostępne. Jest to użyteczne, gdyż widoki są często konstruowane by obsłużyć wiele zdarzeń na stronie. W takim przypadku serwer obsługuje wiele żądań zanim przejdzie na następny widok. Zdefiniowane zmienne są dostępne dla każdego żądania które zostało wygenerowane dla danego widoku.
Aby zdefiniować instancje zmiennej w zakresie widoku, należy użyć elementu var w środku definicji view-state:
<view-state id="enterSearchCriteria">
<var name="searchCriteria" class="com.mycompany.myapp.hotels.search.SearchCriteria"/>
</view-state>
b) Używanie ziaren Springa w zależności od zakresu
Choć definicje automatycznie połączonych instancji zmiennych przepływu daje nam dobrą modularyzacje i czytelność, to czasem mogą powstać okazje w których chcielibyśmy używać innych możliwości kontenera springa. W tych przypadkach możemy zdefiniować ziarno w Spring ApplicationContext i dać mu specyficzny zakres widoczności:
<bean id="searchCriteria" class="com.mycompany.myapp.hotels.search.SearchCriteria" scope="flow"/>
Główną różnicą w tym podejściu jest to że ziarno nie zostanie do końca zainicjalizowane aż do pierwszego odwołania, poprzez język wyrażeń. (EL)
Ten rodzaj powolnej inicjalizacji poprzez EL jest podobny do zarządzania alokacją ziaren przez JSF.
c) Zmiany w modelu.
Potrzeba inicjalizacji modelu przed jego renderowaniem (np. pobieranie informacji z bazy danych) jest często spotykana. Mechanizmy JSF nie zapewniają żadnego dogodnego rozwiązania do inicjalizacji takich obiektów.
Język definicji przepływu wprowadza naturalne sposoby na taką inicjalizacje, poprzez akcje.
Spring Faces udostępnia nam dodatkowe narzędzia do konwenterowania wyników akcji do specyficznych struktur danych JSF.
np:
<on-render>
<evaluate expression="bookingService.findBookings(currentUser.name)"
result="viewScope.bookings" result-type="dataModel" />
</on-render>
To polecenie weźmie rezultat z metody bookingService.findBookings i opakuje je w dowolny model danych JSF.
Dzięki temu lista może być używana w standardowym komponencie tabeli danych JSF'a
<h:dataTable id="bookings" styleClass="summary" value="#{bookings}" var="booking" rendered="#{bookings.rowCount > 0}">
<h:column>
<f:facet name="header">Name</f:facet>
#{booking.hotel.name}
</h:column>
<h:column>
<f:facet name="header">Confirmation number</f:facet>
#{booking.id}
<h:column>
<h:column>
<f:facet name="header">Action</f:facet>
<h:commandLink id="cancel" value="Cancel" action="cancelBooking" />
</h:column>
</h:dataTable>
Domyślny Model danych udostępnia pewne dodatkowe nowości, takie jak możliwość serializacji elementów dla zakresu żądania i dostęp do aktualnie zaznaczonych rzędów z poziomu języka wyrażeń. Np. w przypadku powrotu z widoku w którym zdarzenie akcji zostało wywołane przez komponent znajdujący się w DataTable, możemy ustalić akcje na zaznaczonym rzędzie instancji modelu tabeli:
<transition on="cancelBooking">
<evaluate expression="bookingService.cancelBooking(bookings.selectedRow)" />
</transition>
ZARZĄDZANIE ZDARZENIAMI JSF Z UŻYCIEM SPRING WEBFLOW
Spring Web Flow pozwala na obsługę zdarzeń akcji JSF w oddzielny sposób, nie wymagając bezpośrednich zależności w kodzie Javy w JSF API.
Zdarzenia mogą być całkowicie obsługiwane w języku definicji przepływu, bez potrzeby użycia jakiegokolwiek kodu Javy. Pozwala to na swobodne podejście do procesu tworzenia projektu. Dokumenty są zarządzane poprzez połączenie zdarzeń ( Szablonów widoku JSF i definicji przepływu WebFlow) i natychmiastowo odświeżane bez konieczności przebudowywania całego projektu lub ponownego wrażania na serwer.
a) Obsługa zdarzeń akcji JSF na stronie
Gdy używamy JSF bardzo często zdarza się, że potrzebujemy wskazać zdarzenie, które powoduje jakieś zmiany w modelu, a następnie ponownie wyświetla stronę z uwzględnieniem zmian. Język definicji przepływu posiada element transition, który to obsługuje.
Dobrym przykładem takiego zdarzenia jest tabela zawierająca stronicowane listy wyników. Załóżmy, że chcemy ładować i wyświetlać tylko część list wyników, a także
pozwalać użytkownikowi na przeglądanie wszystkich list strona po stronie.
Początkowa definicja ładowania i wyświetlania list może wyglądać następująco:
<view-state id="reviewHotels">
<on-render>
<evaluate expression="bookingService.findHotels(searchCriteria)"
result="viewScope.hotels" result-type="dataModel" />
</on-render>
</view-state>
W naszym przypadku będziemy tworzyć listę hoteli. W tym celu konstruujemy tabelę danych JSF, która wyświetli bieżące wyniki, a następnie umieszczamy pod tabelą link "More Results", który będzie kierował nas do kolejnych stron z wynikami.
<h:commandLink id="nextPageLink" value="More Results" action="next"/>
Element CommandLink obsługujący link w swoim atrybucie action wskazuje na zdarzenie "next". Możemy obsłużyć to zdarzenie poprzez dodanie do elementu view-state następującego kodu:
<view-state id="reviewHotels">
<on-render>
<evaluate expression="bookingService.findHotels(searchCriteria)"
result="viewScope.hotels" result-type="dataModel" />
</on-render>
<transition on="next">
<evaluate expression="searchCriteria.nextPage()" />
</transition>
</view-state>
W naszym przykładzie zdarzenie "next" jest obsługiwane poprzez zwiększanie licznika strony w elemencie searchCriteria. Akcja on-render jest wywoływana ponownie z uaktualnionymi kryteriami wyszukiwania, co powoduje że następna strona z wynikami jest ładowana w modelu danych. Sam widok jest ponownie renderowany, ponieważ element transition nie zawierał atrybutu to i następnie zmiany w modelu są wyświetlone na stronie.
b) Obsługa zdarzeń akcji JSF
Kolejnymi zdarzeniami do omówienia są zdarzenia wymagające nawigacji do innego widoku, zmieniające przy okazji model.
Obsługa tych zdarzeń przy użyciu tylko JSFa, wymagałaby dodania zasady nawigacji do pliku faces-config.xml i i prawdopodobnie dodania pośredniego kodu Javy do komponentów zarządzanych JSF (managed bean). Oba te zadania wymagałyby wdrożenia. Używając języka definicji przepływu, możemy obsłużyć te zdarzenia w prosty sposób, w jednym miejscu, tak jak są obsługiwane zdarzenia na stronie.
Kontynuując nasz przykład załóżmy, że chcemy, aby każdy wiersz w tabeli zawierał link do strony, która posiadałaby szczegółowe informacje na temat elementu tego wiersza.
Aby to otrzymać, możemy dodać do tabeli kolumnę zawierającą następujący element commandLink:
<h:commandLink id="viewHotelLink" value="View Hotel" action="select"/>
W ten sposób dodamy zdarzenie "select", które zostanie obsłużone w dodatkowym elemencie transition w view-state:
<view-state id="reviewHotels">
<on-render>
<evaluate expression="bookingService.findHotels(searchCriteria)"
result="viewScope.hotels" result-type="dataModel" />
</on-render>
<transition on="next">
<evaluate expression="searchCriteria.nextPage()" />
</transition>
<transition on="select" to="reviewHotel">
<set name="flowScope.hotel" value="hotels.selectedRow" />
</transition>
</view-state>
W naszym przykładzie, zdarzenie "select" zostało obsłużone poprzez umieszczenie aktualnie zaznaczonego hotelu z tabeli w zmiennej której zakres ważności odnosi się do przepływu
i w ten sposób "reviewHotel" w view-state może się do niego odwołać.
c) Przeprowadzanie walidacji modelu
JSF zapewnia użyteczne funkcje walidacji danych wejściowych, zanim zmiany zostaną zachowane w modelu. Jednak, gdybyśmy potrzebowali bardziej skomplikowanej walidacji przeprowadzonej już po tym jak zmiany zostały zatwierdzone, wtedy walidacja taka wymagałaby dodania rozbudowanego kodu do metod akcji JSF znajdujących się w komponentach zarządzanych (managed bean).
Taka walidacja jest zadaniem samego modelu, jednak otrzymanie wiadomości o błędach z powrotem na stronę wiązałoby się z dodaniem niepożądanych zależności w API JSF.
Wykorzystując Spring Faces możemy użyć nisko-poziomowy mechanizm MessageContext w kodzie logiki biznesowej i w ten sposób wszystkie dodane tam wiadomości będą dostępne dla FacesContext.
Załóżmy, że mamy stronę, na której użytkownik wpisuje informacje niezbędne do zakończenia rezerwacji hotelu. Musimy zapewnić, że daty zameldowania i wymeldowania użytkownika będą zgodne z ustalonymi zasadami.
Używając elementu transition możemy stworzyć następujący model walidacji:
<view-state id="enterBookingDetails">
<transition on="proceed" to="reviewBooking">
<evaluate
expression="booking.validateEnterBookingDetails(messageContext)" />
</transition>
</view-state>
W tym przypadku zdarzenie "proceed" jest obsługiwane przez odwołanie do metody walidacji na przypadku booking (rezerwacja), podając ogólny przypadek MessageContext tak, że wiadomości mogą być rejestrowane. Wiadomości mogą być wyświetlane wraz z innymi wiadomości JSF poprzez użycie komponentu h:messages.
d) Obsługa zdarzeń Ajaxa
Spring Faces dostarcza specjalne komponenty UIcommand, które rozszerzają standardowe komponenty JSF poprzez dodanie zdolności do aktualizacji widoków opartych na Ajaxie.
Te komponenty są redundantne, a co za tym idzie, użytkownik korzystający z przeglądarki która ich nie obsługuje będzie posiadał identyczne funkcjonalności ( nie utraci zdolności przechodzenia pomiędzy konkretnymi stronami), z wyłączeniem komponentów nie obsługiwanych.
Komponenty Ajax Spring Faces wymagają JSF 1.2.
Wracając do wcześniejszego przykładu ze stronicowaną tabelą, możemy zmienić link
"More Results" tak, aby użyć Ajaxowego żądania , poprzez zastąpienie CommandButton
wersją z Spring Faces (należy pamiętać, że komponenty poleceń Spring Faces domyślnie używają Ajaxa, ale możemy też wymusić na nich użycie nie -Ajaxowych zatwierdzeń formularzy ustawiając ajaxEnabled = "false" na komponencie):
<sf:commandLink id="nextPageLink" value="More Results" action="next" />
Zdarzenie to jest obsługiwane tak samo jak w przypadku bez użycia Ajaxa, czyli poprzez element transition.
Jednak teraz wymagane jest dodanie specjalnej akcji render, określającej które części z drzewa komponentów muszą być ponownie renderowane:
<view-state id="reviewHotels">
<on-render>
<evaluate
expression="bookingService.findHotels(searchCriteria)"
result="viewScope.hotels" result-type="dataModel" />
</on-render>
<transition on="next">
<evaluate expression="searchCriteria.nextPage()" />
<render fragments="hotels:searchResultsFragment" />
</transition>
</view-state>
Element fragments="hotels:searchResultsFragment" jest instrukcją, która zostanie zinterpretowana, tak że tylko komponent z JSF clientId "hotels:searchResultsFragments" zostanie renderowany i zwrócony do klienta. Następnie fragment ten zostanie automatycznie zastąpiony na stronie.
Atrybut "fragments" może być rozdzieloną przecinkami listą identyfikatorów, z których każde id reprezentuje węzeł korzenia poddrzewa (czyli węzeł korzenia i wszystkich jego dzieci), który ma być renderowany. Jeśli zdarzenie "next" jest uruchomione w nie-Ajaxowym żądaniu (np. gdy JavaScript jest wyłączony po stronie klienta), akcja render zostanie zignorowana, a cała strona będzie renderowana normalnie.
W Spring Faces oprócz komponentu commandLink istnieje także komponent commandButton, posiadający taką samą funkcjonalność.
Istnieje także specjalny komponent ajaxEvent, który wywoła akcje JSF w odpowiedzi
na zdarzenie DOM po stronie klienta.
Dodatkową wbudowaną funkcją przy używaniu komponentów Ajax jest możliwość renderowania odpowiedzi, poprzez wykorzystanie widgetu popup,
ustawiając popup = "true" w view-state .
<view-state id="changeSearchCriteria" view="enterSearchCriteria.xhtml" popup="true">
<on-entry>
<render fragments="hotelSearchFragment" />
</on-entry>
<transition on="search" to="reviewHotels">
<evaluate expression="searchCriteria.resetPage()"/>
</transition>
</view-state>
Jeśli "changeSearchCriteria" w view-state zostanie osiągnięty w wyniku Ajaxowego żądania, wynik zostanie renderowany w popupie.
Jeśli Javascript jest niedostępny, żądanie zostanie przetworzone przez pełne odświeżenie okna przeglądarki i widok "changeSearchCriteria" będzie renderowany normalnie.
WALIDACJA PO STRONIE KLIENTA
Połączenie JSF z Web Flow zapewnia dokładny model walidacji po stronie serwera.
Jednakże zbyt duża liczba odwołań do serwera, w celu wykonania walidacji oraz zwracanie komunikatów o błędach, może być uciążliwe dla naszych użytkowników.
Spring Faces zapewnia szereg kontrolerów walidacji po stronie klienta, które poprawiają korzystanie z naszej strony poprzez proste sprawdzanie poprawności dające natychmiastową informację zwrotną.
Poniżej przedstawiamy kilka prostych przykładów.
a) Walidacja pola tekstowego:
Prosta walidacja pola tekstowego po stronie klienta może zostać wykonana poprzez użycie komponentu clientTextValidator:
<sf:clientTextValidator required="true">
<h:inputText id="creditCardName" value="#{booking.creditCardName}" required="true"/>
</sf:clientTextValidator>
W ten sposób po stronie klienta zostanie wykonana walidacja komponentu inputText, zwracająca użytkownikowi odpowiednią informację, jeśli pole to pozostało niewypełnione.
b) Walidacja pola liczbowego:
Prosta walidacja pola liczbowego po stronie klienta może zostać wykonana poprzez użycie komponentu clientNumberValidator:
<sf:clientTextValidator required="true" regExp="[0-9]{16}"
invalidMessage="A 16-digit credit card number is required.">
<h:inputText id="creditCard" value="#{booking.creditCard}" required="true"/>
</sf:clientTextValidator>
W ten sposób po stronie klienta zostanie wykonana walidacja komponentu inputText, zwracająca użytkownikowi odpowiednią informację, jeśli pole to pozostało niewypełnione, nie jest liczbą lub jeżeli nie pasuje do określonych wyrażeń.
c) Walidacja pola zawierającego datę:
Prosta walidacja po stronie klienta dotycząca pola zawierającego datę może zostać wykonana poprzez użycie komponentu clientDateValidator:
<sf:clientDateValidator required="true" >
<h:inputText id="checkinDate" value="#{booking.checkinDate}" required="true">
<f:convertDateTime pattern="yyyy-MM-dd" timeZone="EST"/>
</h:inputText></sf:clientDateValidator>
W ten sposób po stronie klienta zostanie wykonana walidacja komponentu inputText, zwracająca użytkownikowi odpowiednią informację, jeśli pole to pozostało niewypełnione lub jeżeli nie jest poprawną datą.
d) Zapobieganie zatwierdzeniu niepoprawnego formularza
Aby zapobiec sytuacji, w której niepoprawny formularz zostałby zatwierdzony, możemy wykorzystać komponent validateAllOnClick. Komponent ten może zostać użyty, aby przechwycić zdarzenie „onClick” komponentu i zatrzymać zdarzenie, jeśli nie przeszło ono pomyślnie walidacji po stronie klienta.
<sf:validateAllOnClick>
<sf:commandButton id="proceed" action="proceed" processIds="*" value="Proceed"/> 
</sf:validateAllOnClick>
W ten sposób zapobiegniemy zatwierdzeniu formularza w przypadku, gdy użytkownik nacisnął przycisk „proceed”, a formularz ten jest niepoprawny.
W przypadku walidacji po stronie klienta, użytkownik od razu dostaje informacje o błędach, które należy poprawić.
INTEGRACJA Z DODATKOWYMI BIBLIOTEKAMI KOMPONENTÓW
Spring Faces dąży do bycia kompatybilnym z różnymi dodatkowymi bibliotekami komponentów JSF'a.
Biblioteki rozszerzające JSF'a zgodne ze standardową semantyką JSF'a powinny w ogólnym przypadku "być zgodne" i wspierać WebFlow. Główną rzeczą do zapamiętania jest to że konfiguracja web.xml powinna nieznacznie się zmienić jako że żądania Spring Faces nie będą przekierowywane poprzez standardowy FacesServlet.
Typowo, wszystko co jest tradycyjnie mapowane na FacesServlet powinno być mapowane na Spring DispatcherServlet. W niektórych przypadkach, integracja niskiego poziomu może być osiągnięta przez skonfigurowanie specjalnych usług przepływu.
a) Integracja z Rich Faces.
Aby używać komponentów biblioteki Rich Faces ze Spring Faces, potrzebna jest konfiguracja filtru w pliku web.xml; ( jako uzupełnienie typowej konfiguracji Spring Faces)
<filter>
<display-name>RichFaces Filter</display-name>
<filter-name>richfaces</filter-name>
<filter-class>org.ajax4jsf.Filter</filter-class>
</filter>
<filter-mapping>
<filter-name>richfaces</filter-name>
<servlet-name>Spring Web MVC Dispatcher Servlet</servlet-name>
<dispatcher>REQUEST</dispatcher>
<dispatcher>FORWARD</dispatcher>
<dispatcher>INCLUDE</dispatcher>
</filter-mapping>
Dla "głębokiej" integracji ( możliwość tworzenia widoków z kombinacją użycia komponentów Spring Faces Ajax i Ajax Rich Faces), musimy skonfigurować RichFacesAjaxHandler w koltrolerze przepłyu (flow controler)
<bean id="flowController" class="org.springframework.webflow.mvc.servlet.FlowController">
<property name="flowExecutor" ref="flowExecutor" />
<property name="ajaxHandler">
<bean class="org.springframework.faces.richfaces.RichFacesAjaxHandler"/>
</property>
</bean>
Kopomnenty Ajax RichFaces mogą być używane w połączeniu ze znacznikiem render by renderować częściowe fragmenty żądań Ajaxa.
Zamiast umieszczania identyfikatorów komponentów by były przerenderowane bezpośrednio w szablonie widoku ( tak jak się w tradycyjnych Rich Faces), możemy łączyć atrybut reRender komponentów Ajax RichFaces ze specjalnymi zmiennymi języka wyrażeń: flowRenderFragments.
Dla przykładu w twoim szablonie widoku możesz mieć fragment w który chcesz potencjalnie przerenderować w żądaniu do konkretnego zdarzenia:
<h:form id="hotels">
<a4j:outputPanel id="searchResultsFragment">
<h:outputText id="noHotelsText" value="No Hotels Found" rendered="#{hotels.rowCount == 0}"/>
<h:dataTable id="hotels" styleClass="summary" value="#{hotels}" var="hotel" rendered="#{hotels.rowCount > 0}">
<h:column>
<f:facet name="header">Name</f:facet>
#{hotel.name}
</h:column>
<h:column>
<f:facet name="header">Address</f:facet>
#{hotel.address}
</h:column>
</h:dataTable>
</a4j:outputPanel>
</h:form>
Tworzymy Ajax RichFaces commandLink do wywołania zdarzenia:
<a4j:commandLink id="nextPageLink" value="More Results" action="next" reRender="#{flowRenderFragments}" />
A następnie tworzymy definicje przejścia do obsługi tego zdarzenia:
<transition on="next">
<evaluate expression="searchCriteria.nextPage()" />
<render fragments="hotels:searchResultsFragment" />
</transition>
a) Integracja z Apache MyFaces Trinidad.
Biblioteka Apache MyFaces Trinidad została przetestowana pod kątem integracji ze Spring Faces i została poprawiona pod tym kątem. Jednak głęboka integracja która pozwalała by komponentom Trinidad i Spring Faces na współdziałanie nie jest możliwa.
Typowa konfiguracja Trinidad we współdziałaniu ze Spring Faces wygląda w ten sposób: ( bez typowej konfiguracji SpringFaces)
<context-param>
<param-name>javax.faces.STATE_SAVING_METHOD</param-name>
<param-value>server</param-value>
</context-param>
<context-param>
<param-name>
org.apache.myfaces.trinidad.CHANGE_PERSISTENCE
</param-name>
<param-value>session</param-value>
</context-param>
<context-param>
<param-name>
org.apache.myfaces.trinidad.ENABLE_QUIRKS_MODE
</param-name>
<param-value>false</param-value>
</context-param>
<filter>
<filter-name>Trinidad Filter</filter-name>
<filter-class>
org.apache.myfaces.trinidad.webapp.TrinidadFilter
</filter-class>
</filter>
<filter-mapping>
<filter-name>Trinidad Filter</filter-name>
<servlet-name>Spring MVC Dispatcher Servlet</servlet-name>
</filter-mapping>
<servlet>
<servlet-name>Trinidad Resource Servlet</servlet-name>
<servlet-class>
org.apache.myfaces.trinidad.webapp.ResourceServlet
</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>resources</servlet-name>
<url-pattern>/adf/*</url-pattern>
</servlet-mapping>
Artykuł stworzono na podstawie dokumentacji Spring Web Flow.
UPDATE (12.04.2011)
Uaktualniono dokumentacje do najnowszej wersji Springa.
UPDATE (21.06.2011)
Drobne poprawki
EDIT (20.02.2012)
Uwaga: Artykuł opisuje wersję 2.0. Aktualna wersja Spring WebFlow to 2.3.
Część przykładów może być nie aktualna.